Non-Blocking Vs Blocking I/O
· Blocking vs Non Blocking
· Explain Non-Blocking I/O Like I’m Five
∘ Introduction
∘ Your Own Table Factory
∘ Your First Employee and Work Bench
∘ Multiple Employees, Single Workbench
∘ Multitasking, Non-Blocking Employees
∘ Benefits of Non-Blocking I/O
∘ Implementations
∘ Final Thoughts
· C10K Problem — From where Events Loop comes from
· Pills of Non-Blocking I/O: select()/poll()/epoll()
· Short- Vs Long-lived Connections
· Dealing with the I/O — A few Key Models
· Preamble
· Single Threaded Non-Blocking I/O
· Multithreaded Non-Blocking
· Blocking Multithreaded
· Synchronous I/O: Single Thread per Connection.
· Asynchronous I/O: Single Dispatcher Thread, many Worker Threads.
· Event-based web server — let’s build one. (e.g. Nginx)
· Writing a Simple TCP Server Using Kqueue
· References
Follow this link for all System design articles
Blocking vs Non Blocking
- A Blocking I/O operation imposes a stop-the-world pause to the main Process/Thread: the caller waits until the operation is completed.
- On the other hand, a Non-Blocking I/O or Asynchronous I/O operation does not impose any stop-the-world pause to the main Process/Thread: the caller continues its execution, meanwhile in the background the I/O will be completed by the OS.
✅ As intuitive, in the second case, the caller has to either poll a buffer for checking the status, or register a callback to get notified asynchronously upon the completion [3]. - Client code using Non-Blocking I/O is fairly complex, in terms of design and debuggability: a-priori, no assumption can be done about the completion of I/O operation(s), code has to take this into consideration and has to be organized accordingly (events flow out from the channels with non-determinism, buffers are filled up and client code has to carefully deal with these aspects).
- As opposite, Blocking I/O is normally stream oriented: upon the I/O request, the best is done to serve immediately the request and return the data to the caller as the result of the System Call.
- In several instances, non-blocking I/O is a scalable strategy; however, let’s look at an example where this assumption is easily falsified. Consider the example of a single process dealing with a large number of events generated by several File Descriptors (FD).
→ As is obvious, the benefits of Non-Blocking I/O vanish in this scenario: the process is supposed to deal with CPU-bound unit of works (the I/O-bound part is already done, the network events are now in the buffers), serialized in a single software execution path on the underlying resources (i.e. Caches, Memory, etc. ), implying that the CPU must execute each individual event one by one.
Explain Non-Blocking I/O Like I’m Five
https://dev.to/frosnerd/explain-non-blocking-i-o-like-i-m-five-2a5f
Introduction
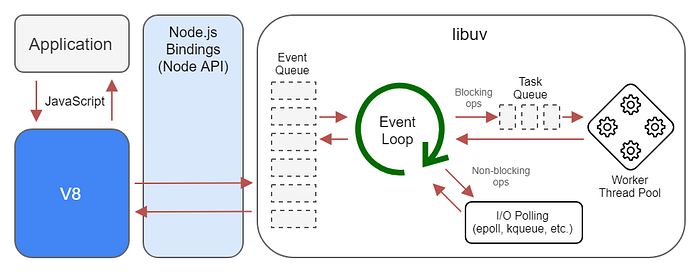
Ten years ago there was a major shift in the field of network application development. In 2009 Ryan Dahl invented Node.js because he was not happy with the limited possibilities of the popular Apache HTTP Server to handle thousands of concurrent connections. The Node.js project combined a JavaScript engine, an event loop, and an I/O layer. It is commonly referred to as a non-blocking web server.
The idea of non-blocking I/O in combination with an event loop is not new. The Java community added the NIO module to J2SE 1.4 already back in 2002. Netty, a non-blocking I/O client-server framework for the development of Java network applications, is actively developed since 2004. Operating systems are offering functionality to get notified as soon as a socket is readable or writable even since before that.
Nowadays you often hear or read comments like “X is a non-blocking, event-driven, scalable, [insert another buzzword here] framework”. But what does it mean and why is it useful? The remainder of this post is structured as follows. The next section will illustrate the concept of non-blocking I/O with a simple analogy. Afterwards we will discuss advantages and disadvantages of non-blocking I/O. The next section allows us to take a glimpse into how non-blocking I/O is implemented in different operating systems. We will conclude the post by giving some final thoughts.
Your Own Table Factory
Your First Employee and Work Bench
Imagine you are starting a business which produces tables. You are renting a small building and buying a single work bench because you only have one employee, let’s call him George. In the morning, George enters the building, goes to the work bench, and picks a new order from the inbox.
Tables vary in size and color. The respective resources and supplies are available in the store room. However sometimes the store room does not have the required materials, e.g. a color is missing, so George has to order new supplies. Because George likes to finish one thing before he starts another, he will simply wait at the work bench until the new supplies are delivered.
In this analogy, the factory represents a computer system, the work bench represents your CPU, and George is a working thread. Ordering new supplies corresponds to I/O operations and you can be seen as the operating system, coordinating all the interactions. The CPU has no multi-tasking capabilities and every operation is not only blocking a thread but the whole CPU and thus the whole computer.
Multiple Employees, Single Workbench
You are wondering if you could increase the productivity by convincing George to work on something else while the supplies are being delivered. It can take multiple days before a new delivery arrives and George will just stand there doing nothing. You confront him with your new plan but he replies: “I’m really bad at context switching, boss. But I’d be happy to go home and do nothing there so I’m at least not blocking the work bench!”.
You realize that this is not what you had hoped for but at least you can hire another employee to work at the bench while George is at home, waiting for the delivery. You are hiring Gina and she is assembling another table while George is at home. Sometimes George has to wait for Gina to finish a table before he can continue his work but the productivity is almost doubled nevertheless, because Georges waiting time is utilized much better.
By having multiple employees sharing the same workbench we introduced a form of multi-tasking. There are different multi-tasking techniques and here we have a very basic one: As soon as a thread is blocked waiting for I/O it can be parked and another thread can use the CPU. In I/O heavy applications this approach however requires us to hire more employees (spawn more threads) that will be waiting. Hiring workers is expensive. Is there another way to increase productivity?
Multitasking, Non-Blocking Employees
In her second week, Gina also ran out of supplies. She realized that it is actually not that bad to simply work on another table while waiting for the delivery so she asks you to send her a text message when the delivery arrived so she can continue working on that table as soon as she finishes her current work or is waiting for another delivery.
Now Gina is utilizing the work bench from 9 to 5 and George realizes that she is way more productive than him. He decides to change jobs, but luckily Gina has a friend who is as flexible as her and thanks to all the tables you sold you can afford a second work bench. Now each work bench has an employee working the whole day, utilizing waiting time for supply deliveries to work on another order in the meantime. Thanks to your notification on arrived deliveries they can focus on their work and do not have to check the delivery status on a regular basis.
After changing the working mode to no longer idle when waiting for deliveries, your employees are perfoming I/O in a non-blocking way. Although George was also no longer blocking the CPU after he started waiting for the delivery at home, he was still waiting and thus blocked. Gina and her friend are simply working on something else, suspending the assembly of the table which requires supplies to be delivered, waiting for the operating system to signal them that the I/O result is ready.
Benefits of Non-Blocking I/O
I hope the previous analogy made it clear what the basic idea of non-blocking I/O is. But when is it useful? Generally one can say that the benefit starts kicking in once your workload is heavily I/O bound. Meaning your CPU would spend a lot of time waiting for your network interfaces, for example.
Using non-blocking I/O in the right situation will improve throughput, latency, and/or responsiveness of your application. It also allows you to work with a single thread, potentially getting rid of synchronization between threads and all the problems associated with it. Node.js is single-threaded, yet can handle millions of connections with a couple of GB RAM without problems.
A common misconception lies in the fact that non-blocking I/O means fast I/O. Just because your I/O is not blocking your thread it does not get executed faster. As usual there is no silver bullet but only trade-offs. There is a nice blog post on TheTechSolo discussing advantages and disadvantages of different concepts around this topic.
Implementations
There are many different forms and implementations of non-blocking I/O. However all major operation systems have built-in kernel functions that can be used to perform non-blocking I/O. epoll is commonly used on Linux systems and it was inspired by kqueue (research paper) which is available in BSD based systems (e.g. Mac OS X).
When using Java, the developer can rely on Java NIO. In most JVM implementations you can expect Java NIO to use those kernel functions if applicable. However there are some subtleties when it comes to the details. As the Java NIO API is generic enough to work on all operating systems, it cannot utilize some of the advanced features that individual implementations like epoll or kqueue provide. It resembles very basic poll semantics.
Thus if you are looking for a little bit of extra flexibility or performance you might want to switch to native transports directly. Netty, one of the best network application framework on the JVM, supports both Java NIO transports as well as native libraries for Linux and Mac OS X.
Of course most of the time you are not going to work with Java NIO or Netty directly but use some web application framework. Some frameworks will allow you to configure your network layer to some extend. In Vert.x, for example, you can choose whether you want to use native transports if applicable and it offers
EpollTransportbased on NettiesEpollEventLoopGroup,KQueueTransportbased onKQueueEventLoopGroup, andTransportbased onNioEventLoopGroup.
Final Thoughts
The term non-blocking is used in many different ways and contexts. In this post we were focusing on non-blocking I/O which refers to threads not waiting for I/O operations to finish. However sometimes people refer to APIs as non-blocking only because they do not block the current thread. But that doesn’t necessarily mean they perform non-blocking I/O.
Take JDBC as an example. JDBC is blocking by definition. However there is a JDBC client out there which has an asynchronous API. Does it block your thread while waiting for the response of the database? No! But as I mentioned earlier, JDBC is blocking by definition so who is blocking? The trick here is simply to have a second thread pool that will take the JDBC requests and block instead of your main thread.
Why is that helpful? It allows you to keep doing your main work, e.g. answering to HTTP requests. If not every requests needs a JDBC connection you can still answer those with your main thread while your thread pool is blocked. This is nice but still blocking I/O and you will run into bottlenecks as soon as your work becomes bound by the JDBC communication.
The field is very broad and there are many more details to explore. I believe however that with a basic understanding of blocking vs. non-blocking I/O you should be able to ask the right questions when you run into performance problems. Did you ever use native transports in your application? Did you do it because you could or because you were fighting with performance issues? Let me know in the comments!
C10K Problem — From where Events Loop comes from
- Around 1999s the problem of managing tens of thousands of active stream-oriented connections on a single server was analyzed, and the terms C10K (i.e. Connections 10K) was coined.
- The analyzed problem (even known as “Apache Problem”) considered a HTTP server operating on a single commodity box and serving tens of thousands of active connections (careful, not requests per seconds) using the Thread-per-Connection model.
- At that time, the reference architecture for the CPU was: single processing unit (aka single core) working in the range of frequencies [166, 300] MHz.
- Clearly, on such an architecture, in a high concurrent scenario, in terms of processing time the cost of multiple context switches is relevant: the throughput decreases as soon as the maximum number of manageable connections is reached.
- 10K active connections for commodity servers was an hard limit in the 1999, so to overcome such limitation reactive programming techniques were applied: Reactor Design Pattern [7] allowed to develop single process and single threaded servers dealing with I/O by using an event loop.
- This solution allowed to overcome the hard limit for many reasons.
✅ Firstly, OSes like Linux did not have real OS-level Thread (only with NTPL [16] Linux 2.6 got such abstraction).
✅ Secondly, on hardware architectures of that time, a Thread Context Switch was an heavyweight operation in terms of elapsed time (CPUs were slow, no hardware-support), strongly impacting the overall Scalability.
✅Finally, again, hardware architectures of that time were not multi core and Hyper-threaded.
Pills of Non-Blocking I/O: select()/poll()/epoll()
- Such System Calls work with File Descriptors(FDs) which abstract resources like Files and Sockets.
- According to the POSIX specification [20], each FD can be associated to one inode [21], and potentially one inode can be linked by multiple FDs.
- An inode is a data structure of the OS Kernel that abstracts the physical resources; in a very simplified version, it may be seen as a buffer — this is the simplification that I will use afterwards.
- FDs’ events can be polled with different mechanisms and using different System Calls [10][11].
- select() and poll() are equivalent System Calls to get access to the events generated by a set of FDs,
✅ actually poll() is a bit more modern and tackles some limitations of select().
✅ epoll() is an evolution of poll(), available only on Linux (select() and poll() with different naming are available on almost all other OS platforms) that simplifies the task to fetch events from a set of FDs; more interesting, it solves a bunch of scalability issues of select() and poll(), the most known is the linear scan problem to detect the FDs getting new events. - As System Calls, select(), poll() and epoll() need a Light Context Switch: User- to Kernel-mode switch.
- The polling frequency is configured programmatically, but for epoll() it cannot go under the millisecond which is a limitation itself; in case of select() and poll() the polling frequency can be set to microseconds. Now, let’s imagine a real case scenario, with a select()/poll() on thousands of FDs and polling each few microsecond.
✅ The question is: is this a scalable approach?
✅ Other question, in such a case, what if only 1 of the thousands of FDs is updated each time? … Food for thoughts! - In [12] an interesting benchmark of application libraries based on epoll() is provided, namely libevent and libev. Below pictures report the outcome from the benchmark sessions.
- I would focus the attention of the time spent in processing the events: as soon as the number of FDs approach 1K, with a small number of active clients, on average 150 microseconds are spent to only deal with the events generated in the benchmark. Such overhead introduced by the event processing is a relevant amount of time that has to be taken into consideration in any real-case scenario.
Short- Vs Long-lived Connections
A distinction has to be made between Short- and Long-lived Connections. A Long-lived connection is normally an interactive session between a Client and a Server (in this category can fall the long data transfers normally executed per chunk); on the other hand, a Short-lived session is normally a 1-off connection established only to fetch some very small data — no needs of successive interactions.
Dealing with the I/O — A few Key Models
Preamble
From a practical perspective, I/O Waits and Context Switches cannot be avoided with the default Network Stacks and System Call APIs shipped with generally available versions of the OSes. Interesting point is: techniques like select()/poll()/epoll() block and wait as programmatically configured, and potentially pull one or many frames of data per System Call (i.e. one Context Switch is likely to retrieve Events from multiple FDs).
Single Threaded Non-Blocking I/O
- Events are pulled from the buffer(s) and processed in sequence by the single execution unit, i.e. a Process and/or Thread.
- Therefore, even if the OS supports multicore Non-Blocking I/O, having a single Process/Thread processing the supposedly CPU-bound events is a performance killer: it turns out to be a basic serialization scheme.
Algorithm
- Wait
- Make System Call to selector()/poll()
- Check if something to do (iterate linearly over FDs, optimized in epoll())
- If nothing to do, Goto (1)
- Loop through tasks
1️⃣ If its an OP_ACCEPT, System Call to accept the connection, save the key
2️⃣ If its an OP_READ, find the key, System Call to read the data
3️⃣ If more tasks Goto (3)
Advantages
- Light Context Switches (User to Kernel mode).
Disadvantages
- Inefficient for Short-lived Connections (Events handling overhead and polling time can outweigh the current amount of work).
- Serial processing (from the Process/Thread perspective).
- Bottleneck (in the Event Loop).
- CPU-bound tasks executed serially kill the performances.
- Complex code.
- Complex debugging.
Multithreaded Non-Blocking
- Events are pulled from the buffer(s) and dispatched on worker Threads: a Puller Thread dispatches events over a set of pre-allocated Worker Threads in a Thread Pool.
- Events processing is concurrent with this dispatching scheme, and can take benefit of native multi core processing of modern hardware architectures.
Algorithm
- Wait
- Make System Call to selector()/poll()
- Check if something to do (iterate linearly over FDs, optimized in epoll())
- If nothing to do, Goto (1)
- Loop through tasks and dispatch to Workers***
1️⃣ If more tasks Goto (3) - Goto (1)
*** For each Worker
- If its an OP_ACCEPT, System Call to accept the connection, save the key
- If its an OP_READ, find the key, System Call to read the data
Advantages
- Light Context Switches (User to Kernel mode).
- Higher Scalability and better Performances in processing CPU-bound tasks.
Disadvantages
- Bottleneck (in the Event Loop).
- Multi processing is driven by a dispatcher, so delayed in time (before to start processing new stuff, a Thread has to be weaken up after the Dispatcher has analyzed the event itself); a time consuming level of indirection.
- Complex Code.
- Complex Debugging.
Blocking Multithreaded
- Each I/O request is served by a single Thread, that parses the request, blocks waiting for the operation to complete and finally processes the data retrieved by the I/O task.
- Threads work independently, they perform the System Calls and implement the overall computation taking advantage of native multi processing capabilities of modern hardware architectures.
Algorithm
- Make System Call to Accept Connection (thread blocks there until we have one)
- Make System Call to Read Data (thread blocks there until it gets some)
- Goto (2)
Advantages
- No evident Bottleneck.
- Pure multi-processing (no level of indirection).
- Better Performances (no need to analyze events).
- Number of runnable Threads is potentially limited by the available Virtual Memory.
- The rule NumberOfCPUs * 2 + 1 is appropriate only in case of hard CPU-bound tasks, here we’re talking about mixed I/O-first and CPU-second tasks.
- Easier Code.
Disadvantages
- Higher number of Context Switches on average.
- Higher memory usage (as many Threads’ stacks as the number of FDs).
- Fairly complex Debugging.
Synchronous I/O: Single Thread per Connection.
- Blocking I/O
- High Concurrency (improved a lot with the advent of NPTL [16])
- As many Threads as I/O FDs
- Memory usage is reasonable high
- Make better use of multi-core machines
- Coding is much simpler, as well as debugging
Asynchronous I/O: Single Dispatcher Thread, many Worker Threads.
- Non-Blocking I/O
- Reduced level of Concurrency (Dispatcher is a bottleneck)
- Many Threads come into play to effectively manage the traffic
- Application handles Context Switching between Clients (Dispatcher Thread/Process): application context needs to be saved to work in an Event Loop (normally, Threads does this into their own stack, and this is managed at Kernel level)
- Memory usage is near optimal
- Coding is much harder, as well as debugging (two levels of Asynchrony: events pulled from the OS’s buffers, and pushed to Threads to process them)
Event-based web server — let’s build one. (e.g. Nginx)
- The main thread opens a socket and reserves the port 80 with listen(2)
- Using epoll/kqueue, wait for many sockets at once; this is the only place where the main thread will block. Only proceed when the kernel informs you that whatever you’ve been waiting for is ready.
- When there’s an incoming request, kernel notifies you epoll/kqueue returns, then accept(2) without blocking. Then start processing the request directly within the main thread.
- When there is an I/O wait (for example, a database query) within a request, register it as well so that the kernel notifies you when the database query is returned. Then immediately return to the epoll/kqueue loop.
- In the app logic, the main thread switches context from accepting a request to processing a request and then sending the response back to the client.
As you can see, this model completely changes how you write an app logic, which can be enormous. You can’t even block on a database query. But reward is also great — epoll/kqueue will enable you to wait for tens of thousands of sockets at the same time, so it will infinitely scale concurrency-wise.
Another good thing is that since everything will run inside a single thread, there’s no race condition which can be agonizing with threaded programs.
A big, serious downside of this model is that you are limited within a single CPU. The main thread does everything, and that means you are confined in a single thread context. When the CPU is saturated, latency will add up.
Which means that it works best when there are many connections but most of them are not active — a chat app is a perfect use case for that.
Writing a Simple TCP Server Using Kqueue
https://dev.to/frosnerd/writing-a-simple-tcp-server-using-kqueue-cah
The basic components of our TCP server will be a listening TCP socket, sockets from accepted client connections, a kernel event queue (kqueue), as well as an event loop that polls the queue. The following diagram illustrates the scenario of accepting incoming connections.

When a client wants to connect to our server, a connection request will be placed on the TCP connection queue. The kernel will then place a new event on the kqueue. The event will be processed by the event loop, which accepts the incoming connection, creating a new client socket. The next diagram illustrates how the newly accepted socket is used to read data from the client.

The client writes data to the newly created connection. The kernel places an event on the kqueue, indicating that there is data to be read on this particular socket. The event loop polls that event and reads from the socket. Note that while there is only socket listening to incoming connections, we are creating a new socket for every accepted client connection.
We can implement the design in the following high level steps, which will be discussed in detail in the following sections.
- Create, bind, and listen on a new socket
- Create new kqueue
- Subscribe to socket events
- Poll for new events in a loop and handle them